Clustering K-Means
ML - Clustering K-Means
Clustering
Clustering is an unsupervised machine learning method that is used when you do not have labels for your data. The goal of clustering algorithms is to segment similar data points into groups; to extract meaning from the data.
Introduction to K-Means Algorithm
K-means clustering algorithm computes the centroids and iterates until we it finds optimal centroid. It assumes that the number of clusters are already known. It is also called flat clustering algorithm. The number of clusters identified from data by algorithm is represented by ‘K’ in K-means.
In this algorithm, the data points are assigned to a cluster in such a manner that the sum of the squared distance between the data points and centroid would be minimum. It is to be understood that less variation within the clusters will lead to more similar data points within same cluster.
Working of K-Means Algorithm
- First, we need to specify the number of clusters, K, need to be generated by this algorithm.
- Next, randomly select K data points and assign each data point to a cluster. In simple words, classify the data based on the number of data points.
- Next, keep iterating the following until we find optimal centroid which is the assignment of data points to the clusters that are not changing any more
- First, the sum of squared distance between data points and centroids would be computed.
- Now, we have to assign each data point to the cluster that is closer than other cluster (centroid).
- At last compute the centroids for the clusters by taking the average of all data points of that cluster.
Python Implementation
Import Modules
import numpy as np
import pandas as pd
from scipy.spatial import distance
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
import seaborn as sns
Centroid Initialization
def centroid_init(X, k):
## randomly pick k random indices without replacement
idx = np.random.choice(len(X), k, replace=False)
## select points with those indices
centroids = X[idx, :]
return centroids
K-means model
Find kmeans class for each point and update centroids
def kmeans_class(X, centroids):
#calculate distance between each point and centroids, result each row shows distance for this point to each centroid
dist = distance.cdist(X, centroids, 'euclidean')
## number of centroids
k = centroids.shape[0]
#minimum distance among all clusters centroids and return indices
clus = np.argmin(dist, axis=1)
#update new centroids points, mean value along each feature column, centroids does not need to be those of points
centroids_new = np.array([X[clus==i,:].mean(axis = 0) for i in range(k)])
return centroids_new, clus
test1 = np.ones((4,4))
test2 = np.full((2,4), 2)
print(test2)
dist = distance.cdist(test1, test2, 'euclidean')
print(dist, dist.shape)
[[2 2 2 2]
[2 2 2 2]]
[[2. 2.]
[2. 2.]
[2. 2.]
[2. 2.]] (4, 2)
Training Model
def kmeans_training(X, k, iterations):
## initializa centroids:
centroids_new = centroid_init(X, k)
## training number of iterations times
for i in range(iterations):
centroids_old = centroids_new
centroids_new, clus = kmeans_class(X, centroids_new)
if np.array_equal(centroids_new, centroids_old):break
return centroids_new, clus
Prepare Data
Data source: https://www.kaggle.com/shrutimechlearn/customer-data
# dataset = pd.read_csv('Mall_Customers.csv', index_col='CustomerID')
dataset = pd.read_csv('Mall_Customers.csv')
dataset = dataset.drop(['CustomerID'],axis=1)
# mapping gender string to int number
dataset['Genre'] = dataset['Genre'].map({'Male': 0,'Female': 1})
# dataset['Genre'] = dataset['Genre'].astype(int)
dataset.head()
| Genre | Age | Annual_Income_(k$) | Spending_Score | |
|---|---|---|---|---|
| 0 | 0 | 19 | 15 | 39 |
| 1 | 0 | 21 | 15 | 81 |
| 2 | 1 | 20 | 16 | 6 |
| 3 | 1 | 23 | 16 | 77 |
| 4 | 1 | 31 | 17 | 40 |
convert dataframe to numpy array and normalize data
dataset = dataset.to_numpy()
print(dataset.shape)
sc = StandardScaler()
sc.fit(dataset)
dataset = sc.transform(dataset)
print(dataset.shape)
(200, 4)
(200, 4)
Cluster Sum of Squares
select variables for each rows: https://stackoverflow.com/questions/23435782/numpy-selecting-specific-column-index-per-row-by-using-a-list-of-indexes
def wcss(X, centroids, cluster):
dist = distance.cdist(X, centroids, 'euclidean')
# print(np.arange(len(X)), np.arange(len(X)).shape)
# dist = dist[:,cluster]
print(dist[0,:], dist.shape)
dist_col = dist[np.arange(len(X)), cluster]
# print(X.shape)
# print(dist.shape)
print(cluster[0], dist_col[0])
return np.sum(dist_col)
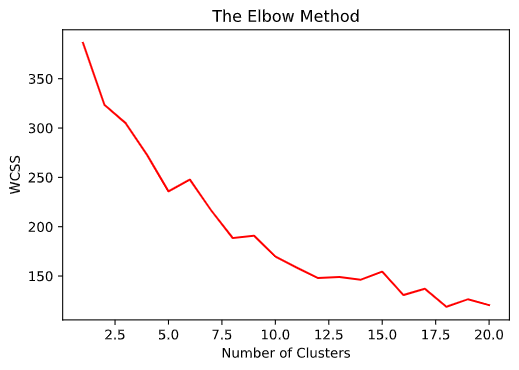
training model using different number of clusters
plt_k = []
plt_y = []
for k in range(3):
centroids, cluster = kmeans_training(dataset, k+1, 100)
wcss_error = wcss(dataset, centroids,cluster)
# print(wcss_error)
plt_k.append(k+1)
plt_y.append(wcss_error)
plt.plot(plt_k,plt_y,'r')
[2.5525074] (200, 1)
0 2.5525074007307538
[2.9655543 2.50447303] (200, 2)
1 2.50447303260962
[2.87644426 3.44800444 2.29058828] (200, 3)
2 2.290588277122288
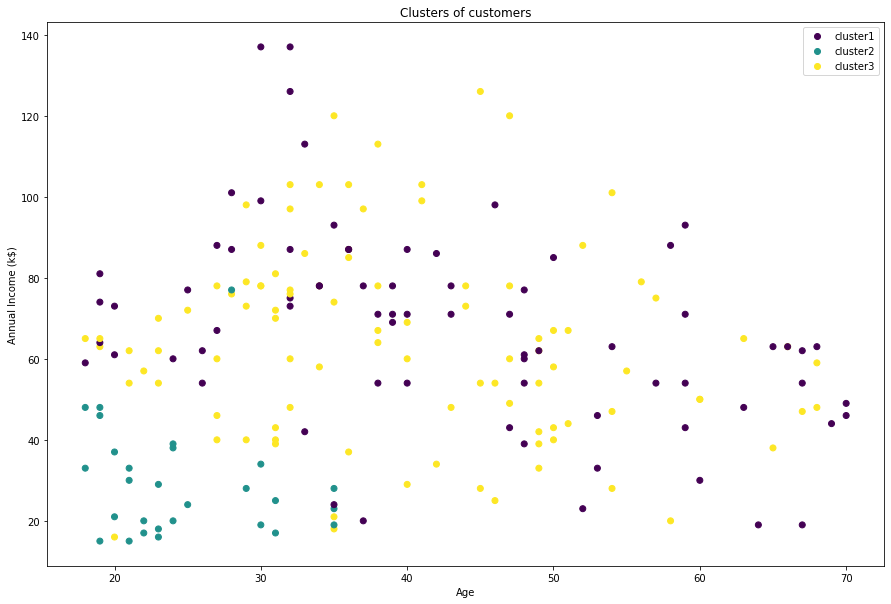
Final plot
## denormalize data
X = sc.inverse_transform(dataset)
plt.figure(figsize=(15,10))
sca = plt.scatter(X[:,1],X[:,2],c=cluster)
labels = ['cluster1', 'cluster2', 'cluster3']
plt.legend(handles=sca.legend_elements()[0], labels=labels)
plt.show()
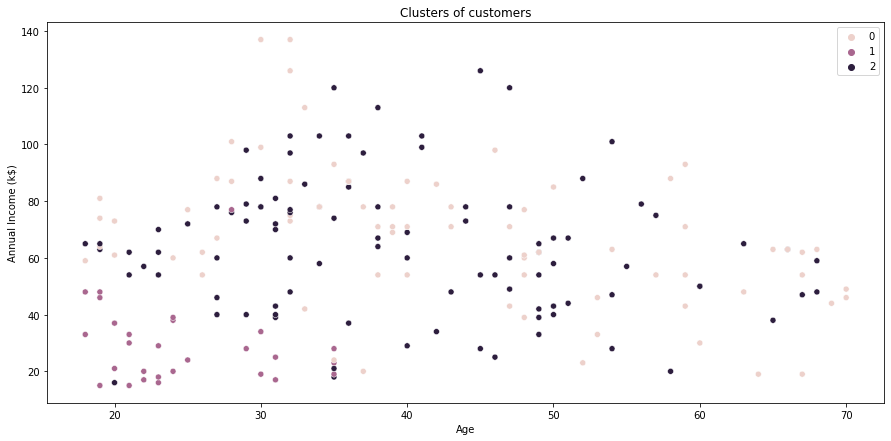
plot using seaborn
plt.figure(figsize=(15,7))
sns.scatterplot(x= X[:,1], y = X[:,2], hue= cluster)
plt.grid(False)
plt.title('Clusters of customers')
plt.xlabel('Annual Income (k$)')
plt.ylabel('Spending Score (1-100)')
plt.legend()
plt.show()
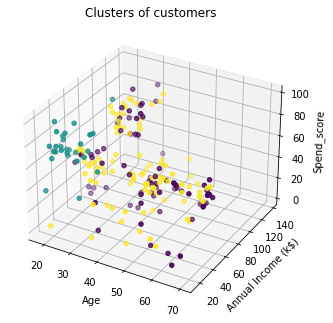
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure()
ax = Axes3D(fig)
ax.scatter(X[:,0],X[:,1],X[:,3],c=cluster)
plt.show()